Conventional speech recognition systems are failing
As previous research has shown, there are many differences between the speech of an adult and that of a child – both acoustically and linguistically. That is why conventional speech recognition systems modelled on adult data are failing to perform satisfactorily on children’s speech input.
Speaking isn’t straightforward
Human speech-production involves a number of articulatory mechanisms and organs interacting in complex ways. Air is exhaled from the lungs and passes through the complex arrangement of organs, as depicted in Figure 1 below.
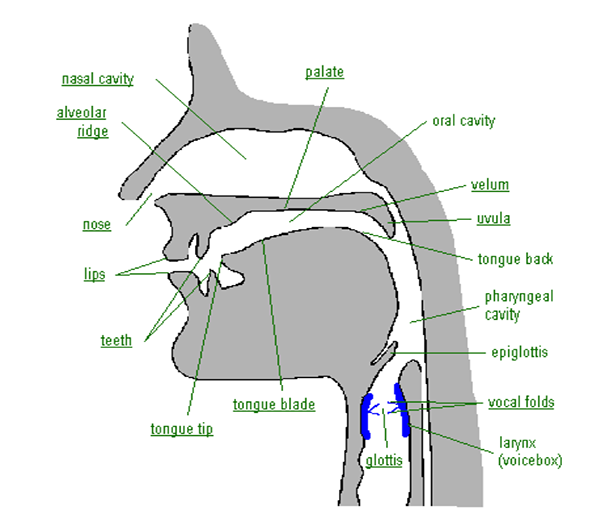
Figure 1. The principal organs of articulation [1]
What are the differences between children and adults?
Children typically have higher fundamental and formant frequencies than those of adults, due to:
- a shorter vocal tract
- smaller vocal folds
- developing articulators (e.g. tongue size and movement)
Formant frequencies play key roles in identifying vowels and voiced consonants as well as determining the phonemic quality. Since children’s vocal tracts are not fully developed, they have a higher pitch than adults when speaking [2,3,4]. The author of [5] provides an in-depth treatment on the acoustical aspects of speech production.
Visualising the differences
In order to visualise the differences in the structure and size of the vocal tracts [6], figure 2 below displays MR-images of both a child and adult female.
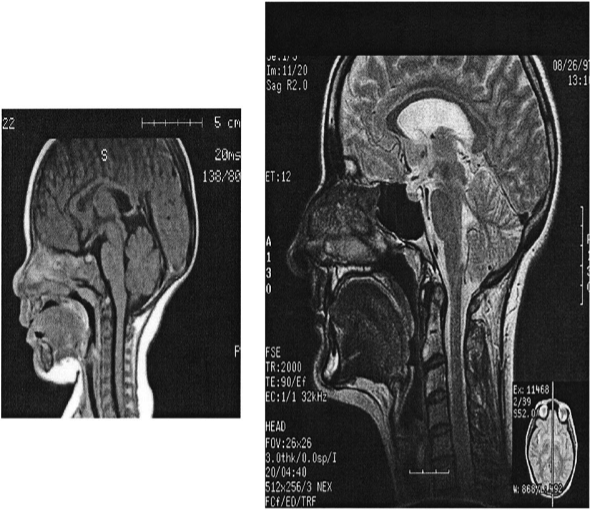
Figure 2. Magnetic resonance images of child and adult females
Drawbacks of the current system
In employing a sampling rate of 16 kHz for audio recordings (a standard way to process audio in current systems), a considerable part of the children’s speech spectrum can be overlooked. This may be one of the drawbacks of conventional automatic speech recognition systems when it comes to children’s speech.
A child may substitute one phoneme with another because they are less experienced speakers, their articulatory inventory is still in development, or even just for fun.
Children are also more likely to use imaginative words, ungrammatical phrases and incorrect pronunciations, as well as to talk about different things compared to adults – all of which present challenges for language modelling and vocabulary selection [4].
So for all of the above-mentioned reasons, building specific language models for children’s speech is essential for improving automatic speech recognition performance.
Have you ever used an automatic speech recognition system yourself or with your children? If so, did you experience any of the difficulties expressed in this article?
References
[1] http://www-01.sil.org/mexico/ling/glosario/e005bi-organsart.htm, on 2014-11-03
[2] Das, S., Nix, D. and Picheny, M. (1998), “Improvements in children’s speech recognition performance”, Proceedings of ICASSP, Seattle, WA, May 1998.
[3] Måhl, Lena (2004), “Speech recognition and adaptation experiments on children’s speech”, Master of Science thesis at the Department of Speech, Music and Hearing, KTH (The Royal Institute of Technology).
[4] Sharmistha Sarkar Gray, Paul Maergner, Nate Bodenstab, Daniel Willett, Joel Pinto, and Jianhua Lu (2014), “Child Automatic Speech Recognition for US English: Child Interaction with Living-Room-Electronic-Devices”, Interspeech 2014 WOCCI Workshop, August 2014.
[5] Kenneth Stevens, “Acoustic Phonetics”, MIT Press, 1999
[6] Houri Vorperian, Ray Kent, Mary Lindstrom, Cliff Kalina, Lindell Gentry and Brian Yandell, “Development of vocal tract length during early childhood: A magnetic resonance imaging study”, Journal of the Acoustical Society of America, January 2005


